장애알림으로 시작하는 상쾌한 월요일입니다? 빅데이터 플랫폼의 클러스터 일부 서버에서 경고 알림이 보고 되었어요. Cloudra Manager 의 서비스 리스트에는 Kafka 서비스에서 Lagging Replicas Test 실패 발생되었다고 경고를 보여주고 있네요. 이번 경우도 문제의 원인은 눈에 보이는 것과는 다르네요. 어떤 일이 있었던걸까요?
Version
- Cloudera CDH 6.1.1
- Cloudera Kafka 2.11-2.0.0-cdh6.1.1
현상파악
Cloudera Manager 확인
3대의 Kafka Broker 중에 01~02 서버에서 경고가보여지고, 03 서버는 정상으로 보여져요. 문제발생한 시간대에 Kafka 로부터 유입되는 데이터의 유실은 다행히 발생하지 않았어요. 먼저 시스템팀에 서버 및 네트워크 이슈가 있었는지 문의했어요. 돌아오는 답변은 항상 같죠.
현상을 정리하면 클러스터는 장애를 극복하고 정상동작하였고, 문제발생한 시간대에 Cloudera Agent 의 로그 수집이 정상적이지 않아 차트의 이빨이 빠졌네요. 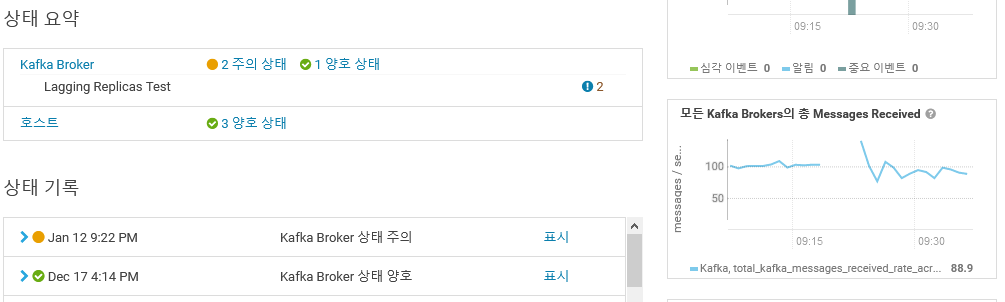
Kafka Manager 확인
Kafka Manger 의 Topics 에서는 Broker Leader Skew, Under Replicated 가 확인되요. 추가로 Brokers Spread 가 150 이라는 거예요. 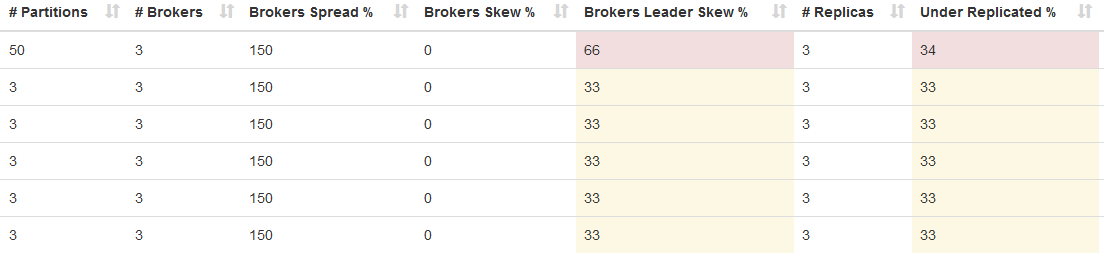
Broker Leader Skew: 리더가 브로커에 균등하게 분산되어 있는지의 퍼센트Under Replicated: 파티션별로 리플리케이션 상태 정보 퍼센트Brokers Spread: 파티션들이 몇개의 브로커에 분산되어 있는지의 퍼센트
Under Replicated, Broker Leader Skew 는 Reassign Partition 을 진행해 주면 되는데, Brokers Spread 수치가 150 이라는게 이상해요. 그래서 더 확인해 보니 Kafka Manager Broker 탭에서 2개의 Broker만 보여지네요.
Reassign Partition진행과정은 일전에 포스팅한 내용이 있어요.
현상을 정리하면 클러스터에서 Kafka 서비스의 Broker 03을 클러스터에서 제거했고, Kafka Manager 는 Skew, Under Replication 을 보고 했어요.
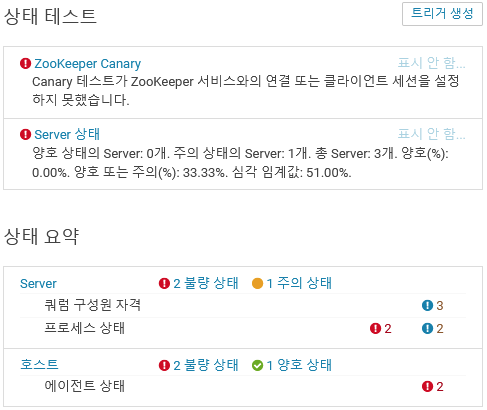
Kafka Broker 가 제거된 이유
Kafka Broker 03 서버 로그를 확인해요. Cached zkVersion… 라는 로그가 보여요. Zookeeper 관련 문제로 파악되죠. 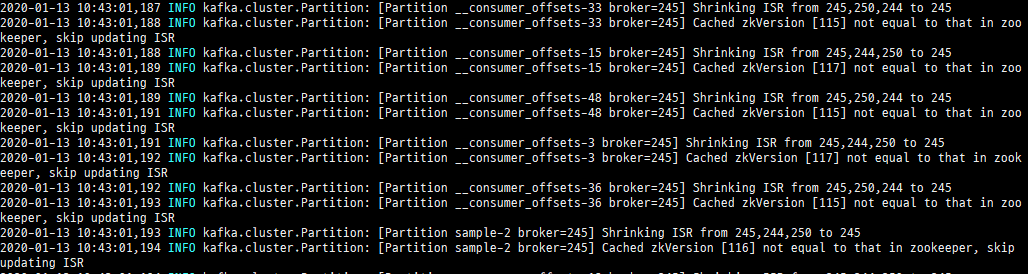
Cloudera Manager Zooker 서비스의 이력을 확인하니 Zookeeper 서버들의 호스트에 불량상태 이력이 보이네요. 

이때 Zookeeper 3대 서버중 2대의 서버에 5분사이에 네트워크 단절이 다수 발생했다는 보고를 받았어요.
현상을 정리하면 Zookeeper 서버에 네트워크 연결실패가 발생했어요. 과정에서 epoch 불일치가 발생하고 Broker 내 파티션들의 ISR 상태를 유지할 수 없어 Broker 03 을 클러스터에서 제거했을 거예요.
1개의 브로커되면서 3개의 파티션을 가진 토픽의 리더와 파티션들은 Broker Leader Skew 33%, Brokers Spread 150% 으로 불일치를 보여요. 1개 브로커가 보유하던 Replica 들만큼의 Under Replicated 33% 발생해요.
조치사항
Cloudera Community, Stack overflow, Jira KAFKA-2729, Jira KAFKA-3042
동일한 증상을 경험한 글들을 확인할 수 있어요. Cloudera Manager 에서 Broker03 재시작 했어요. Shutdown 과정에서 Broker 를 사용할 수 없다는 보그를 보이면서 재시작은 정상적으로 진행되요. Kafka Manager 에서 새로 추가된 Broker 를 확인할 수 있고 각 토픽의 ISR 또한 정상으로 전환되었어요. 